IA et data science au service de l’analyse de discours

Dans un écosystème informationnel saturé, la valeur réside moins dans la possession de la donnée que dans la capacité à en extraire ce qui compte et peut nourrir une lecture stratégique. Mais comment procéder, et par quels outils ?
À titre d'illustration, nos travaux récents sur les débats de la 17e Législature de l’Assemblée nationale (2024-2025) ont permis d'analyser plus de 150 000 interventions, représentant un corpus dépassant les 10 millions de mots. Voici quelques piliers méthodologiques qui permettent à une solution IA-data science de dépasser la simple lecture humaine.

Ingénierie de la donnée : construire la base de connaissance
La portée de l’analyse sémantique repose avant tout sur la qualité et la structure du corpus. Pour ce projet, Youmean a mis en place une chaîne de traitement de données (ETL) robuste, capable d'unifier des sources d'informations hétérogènes.
Le travail débute par la récupération des données en Open Data de l'Assemblée nationale. Nous avons développé des scripts de collecte automatisés pour extraire les comptes rendus intégraux des débats.
Un verbatim sans contexte est une donnée aveugle. Notre code réalise un travail de réconciliation systématique pour enrichir chaque ligne de texte avec des métadonnées critiques, issues des bases de données disponibles en open data et de leurs jointures :
Identité et appartenance. Liaison dynamique entre les interventions et la table des acteurs (députés, ministres) pour suivre les trajectoires individuelles et les changements de groupes.
Temporalité et législature. Structuration chronologique permettant des analyses comparatives entre différentes sessions ou périodes législatives.
Typologie des débats. Classification par nature de séance (questions au gouvernement, examen de texte de loi, etc.).
Indexer les discours par leur mot : le moteur lexical
Avant toute analyse, le texte subit une phase de normalisation linguistique :
Lemmatisation. Réduction des mots à leur forme racine (le "lemme") pour regrouper les variations d'un même concept.
Filtrage de précision. Elimination du "bruit" procédural et des termes vides (stopwords) pour ne laisser que la substance politique.
Indexation SQL. Structuration dans une base de données optimisée pour permettre des calculs statistiques en temps réel sur des millions d'occurrences.
Cette maîtrise complète de la chaîne de valeur — de la collecte brute à l'indexation lexicale — assure la traçabilité et l'intégrité de chaque insight produit par nos algorithmes.
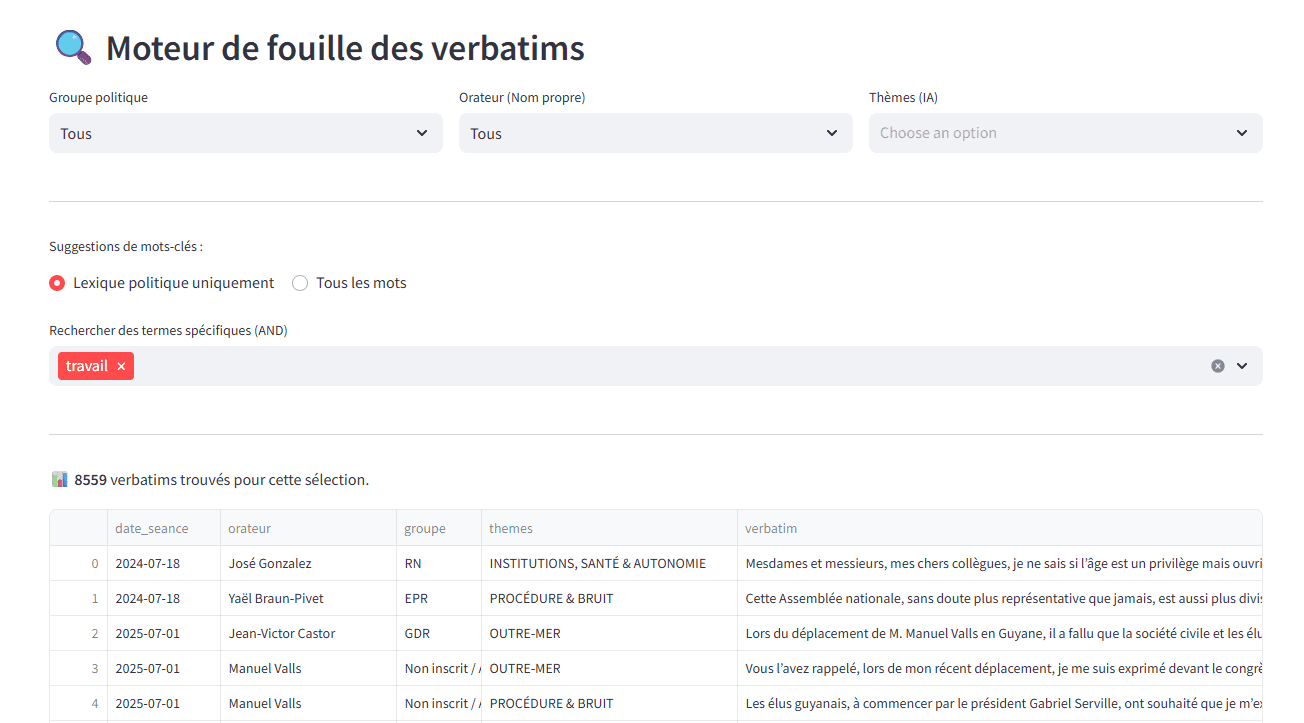
L’indexation lexicale et sémantique d’une base de données textuelles est une étape indispensable. Elle permet déjà de produire un moteur de fouille rapide sur l’ensemble du corpus, mais aussi de qualifier chaque contenu afin de guider des IA génératives (RAG). La fréquence relative des mots et des thèmes est par ailleurs une information nécessaire pour divers algorithmes de data science.
L’IA comme "lecteur augmenté"
Pour traiter cette masse textuelle, il est aussi nécessaire de thématiser chaque intervention. Non pas seulement indexer les mots, mais identifier les sujets structurants. Nous mobilisons usuellement pour cela des grands modèles de langage LLMs fine tunés. Ici, nous avons choisi des SLM - Small Language Models), tels que Ministral Edge 3-8B, qui ont l’avantage d’être déployés localement et qui obtiennent aujourd’hui des scores très convaincants pour détecter le thème d’un contenu parmi une vingtaine de choix.
Nous appliquons un protocole de génération augmentée par la recherche (RAG). L'IA est contrainte d'opérer dans un périmètre de données strictement délimité par les transcriptions officielles. Ce choix technique garantit :
L'absence d'hallucination. Chaque synthèse est sourcée dans le corpus.
La neutralité analytique. Le modèle identifie les thématiques sans projection idéologique.
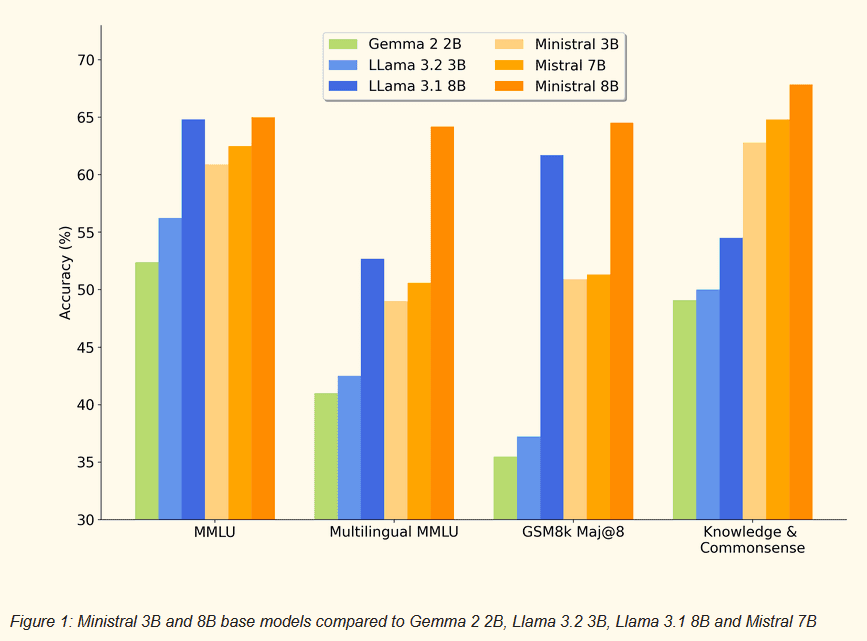
Un modèle comme Ministral a de bonnes performances pour thématiser des batch de verbatims. Avantage : il est souverain, léger et exploitable en local. Sur nos tests, la compréhension de Ministral était meilleure que les concurrents Gemma, Llama.
La signature lexicale : identifier l'empreinte politique
L'une des fonctions de notre outil est l'établissement de "cartes d'identité" basées sur la spécificité statistique du discours d’un groupe politique ou d’un élu en particulier. Plutôt que de comptabiliser les mots les plus fréquents (souvent peu discriminants), nous utilisons un indice de spécificité.
Cet indice compare l'usage d'un terme par un individu ou un groupe par rapport à la moyenne de l'hémicycle :
Indice = (Fréquence du mot chez l'élu / Volume total de l'élu) ÷ (Fréquence globale du mot / Volume total du corpus)
(Fréquence chez l'élu : nombre de fois où le mot est cité par l'acteur ; volume total de l'élu : nombre total de mots prononcés par cet acteur ; fréquence globale : nombre total d'occurrences du mot dans toute l'Assemblée ; volume total du corpus : nombre total de mots dans la base de données)
Cette approche permet d'isoler les marqueurs priorités thématiques et singularités sémantiques de chaque acteur.
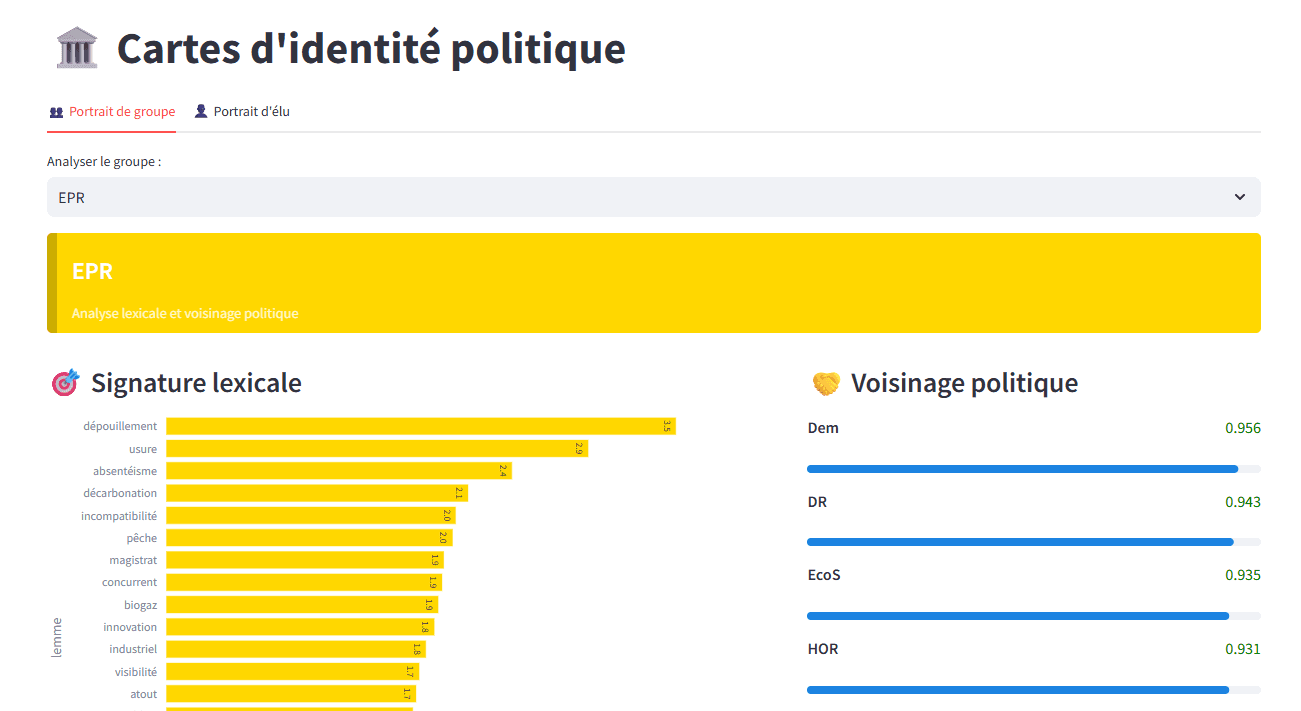
Le principe de la carte d’identité : comparer de la fréquence des mots structurant les discours et mesurer les proximités (entre groupes, ou entre élus). Ici l’expression du groupe EPR.
Analyse factorielle : visualiser les distances idéologiques
Pour visualiser les antagonismes et proximités au sein de l'Assemblée, nous utilisons des algorithmes de réduction de dimensionnalité, comme l'analyse factorielle des correspondances (AFC).
Cette méthode projette les acteurs et les lexiques sur un plan cartésien, où la proximité géométrique traduit une similarité de discours.
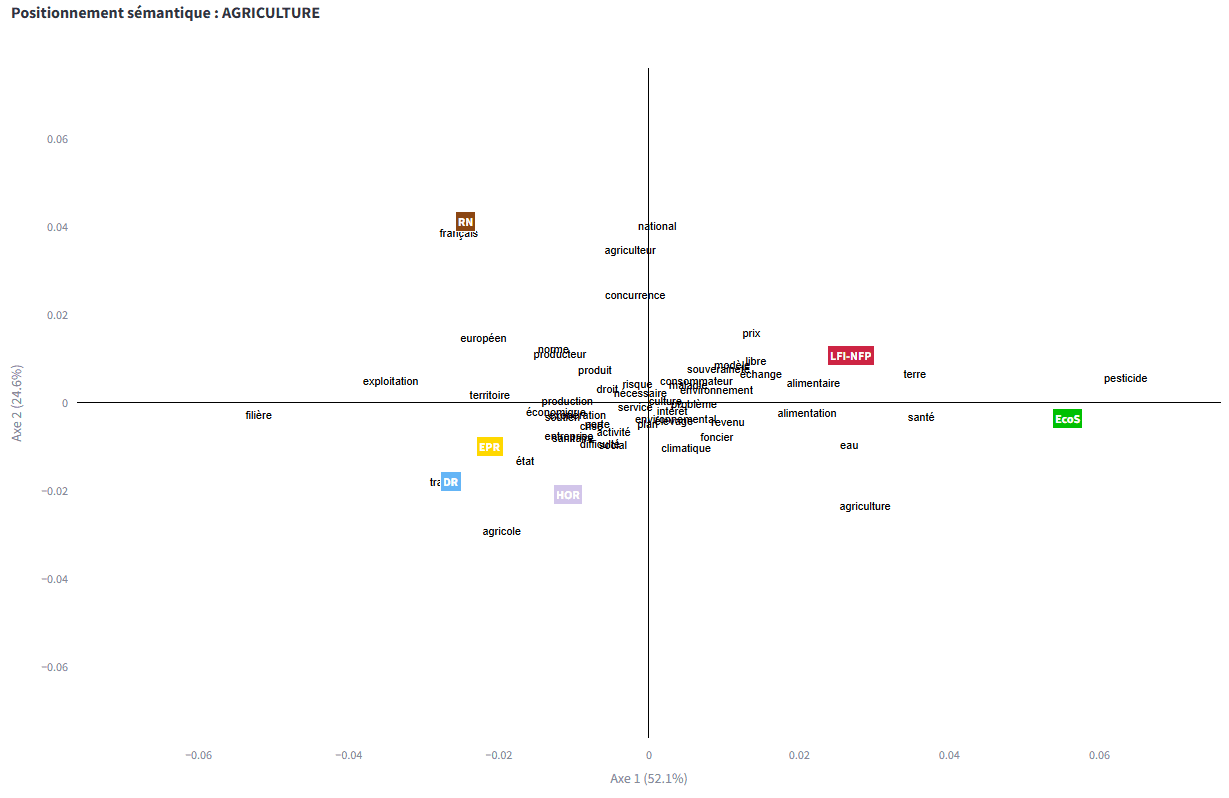
Exemple d’analyse factorielle sur le positionnement de 6 groupes politiques autour des topiques d’un thème (agriculture). Ce type d’analyse permet de détecter les proximités idéologiques entre acteurs, en fonction des sujets qu’ils préfèrent mettre en avant.
Analyse des communautés de mots : ce qui structure les arguments politiques
En complément et pour approfondir la finesse d’analyse, nous appliquons des algorithmes de détection de communautés sur des graphes de co-occurrences.
Cette technique de data science et de visualisation permet de segmenter le discours en "clusters" thématiques et d'observer comment les univers d'expression se forment dans la parole de chaque orateur (ou des groupes en totalité).
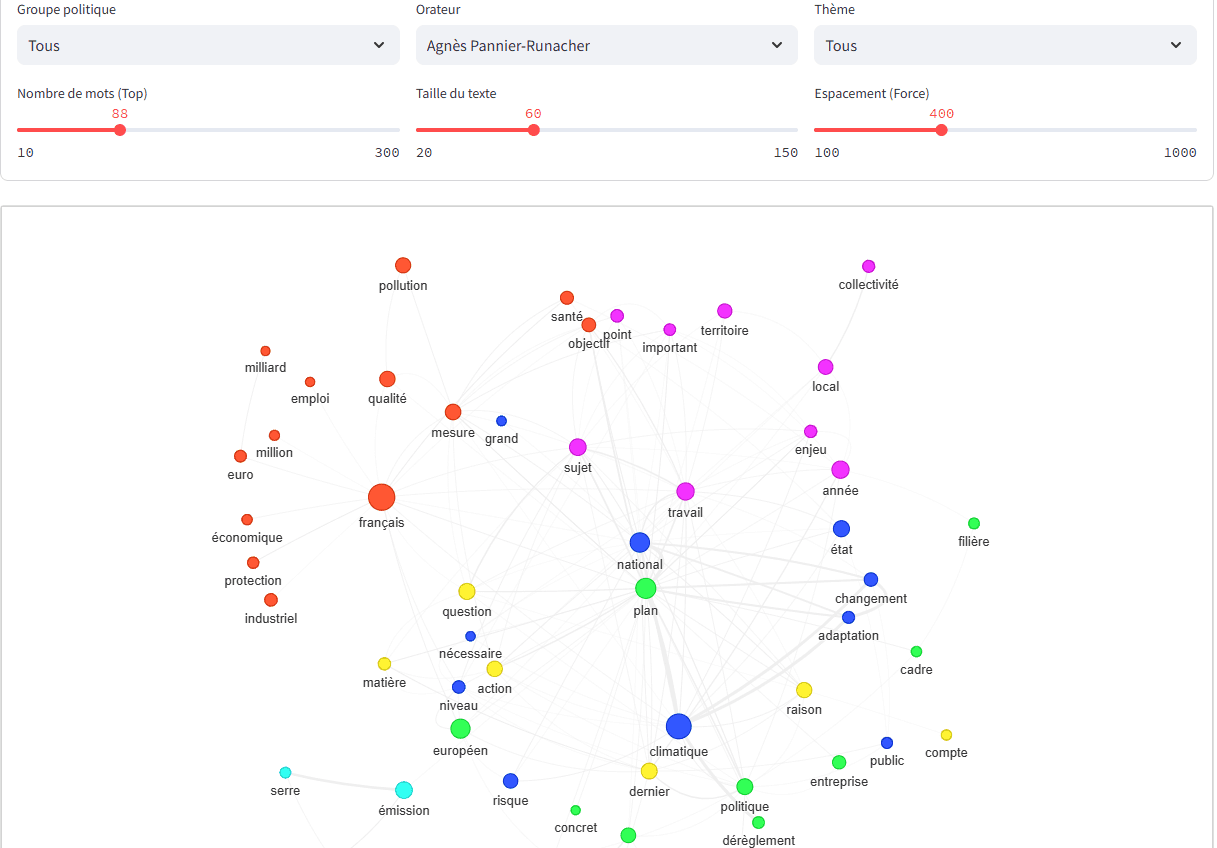
Exemple d’analyse et représentation des clusters de mots d’un orateur de l’Assemblée nationale.
Leadership sémantique : détecter l'occupation du terrain
Grâce aux treemaps de densité, nous mesurons ce que nous appelons le "leadership sémantique". Cette visualisation hiérarchique permet de voir instantanément quel groupe ou quel orateur sature l'espace sur un mot-clé ou un concept précis.
Utilité : identifier les leaders d'opinion naturels et les experts thématiques.
Précision : la surface de chaque bloc reflète fidèlement le poids relatif dans le débat, offrant une lecture immédiate de la domination thématique.
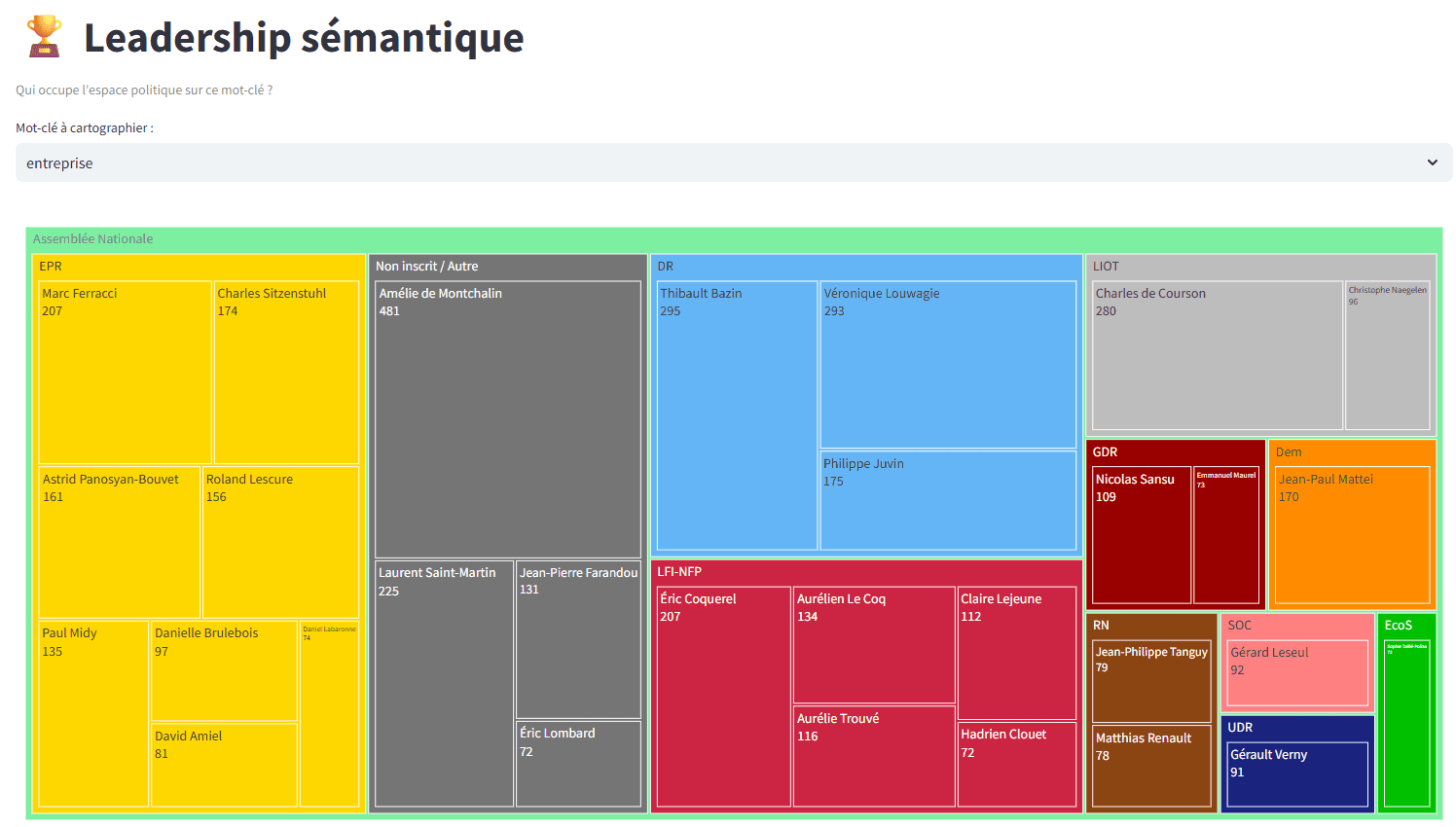
Classique mais efficace : le treemap permet de voir d’un coup d’oeil quels groupes (et au sein des groupes quels élus) préemptent l’expression sur un thème donné.
Flux thématiques : visualiser le "cadrage" (framing)
La perception d'un sujet dépend de la manière dont il est présenté. Nous utilisons des diagrammes de Sankey pour tracer la trajectoire de la parole politique. Le flux part d'un thème général, se divise en groupes, pour aboutir aux mots-clés spécifiques.
Cette technique de visualisation met en lumière le phénomène de cadrage sémantique : elle montre comment une thématique unique est "capturée" par différents acteurs qui la traduisent dans des lexiques différents. C’est une visualisation efficace de la stratégie de communication politique.
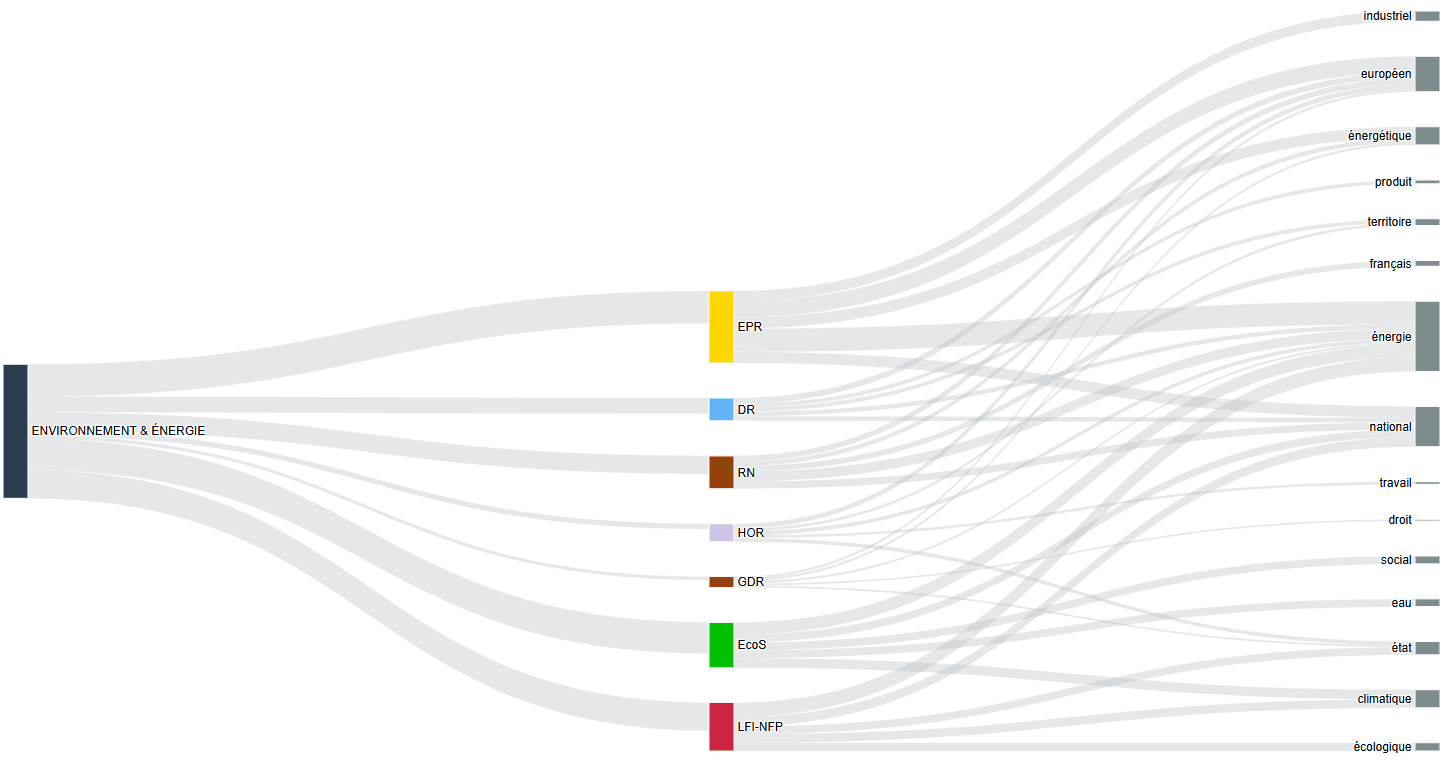
Diagramme de Sankey du thème Environnement & Energie sur les 7 groupes politiques qui en parlent le plus à l’Assemblée.
L’IA générative en rédaction de rapport
Au-delà de l’exploration visuelle, notre plateforme intègre enfin un module de reporting automatisé fondé sur une architecture de génération augmentée par la recherche (RAG). La puissance de cet outil réside dans la qualité de l’indexation et de la thématisation préalable de la base de données. En amont, chaque intervention a été segmentée et qualifiée, permettant à l’IA de puiser exclusivement dans un contexte sémantique riche et vérifié. Cette préparation rigoureuse de la donnée est indispensable pour fournir des synthèses pertinentes.
Grâce à ce RAG et à un fine prompting méticuleux — un pilotage précis des instructions — , nous contraignons l'IA à une analyse factuelle stricte, éliminant tout risque d'hallucination. Le résultat est une capacité de synthèse unique qui transforme, en quelques secondes, des millions de mots en rapports structurés et directement exploitables.
Conclusion : du texte à la stratégie
L'alliance de la data science et de l'IA ne vise pas à remplacer l'expertise humaine, mais à l'amplifier. En rendant la parole mesurable, spatialisée et traçable, les plateformes développées par Youmean offrent une profondeur d'analyse inédite.
Si les débats parlementaires constituent ici un cas d'école intéressant par leur complexité, nos technologies sont conçues pour être déployées sur mesure en fonction de chaque besoin métier et de chaque livrable attendu. Que ce soit pour décrypter la voix de vos clients, cartographier les stratégies de vos concurrents ou analyser des corpus de communication interne, nous calibrons nos algorithmes et nos codons nos interfaces pour répondre à vos enjeux spécifiques.
Pour les décideurs, c’est la garantie de transformer des flux textuels massifs en une vision stratégique claire, permettant d’anticiper les ruptures et de maîtriser, avec une précision chirurgicale, les enjeux du discours au sein de leur propre écosystème.
