Ingénierie de la connaissance pour un RAG expert de l'eau
Territoires
Communication

Dans les projets RAG métier, la performance ne dépend pas seulement du modèle choisi. À partir d'un cas métier, une plateforme d’expertise dédiée à l’eau, cet article montre comment la qualité du corpus, la séparation des sources et les prompts spécialisés deviennent les vrais leviers d’une IA fiable et exploitable.
Les projets d’intelligence artificielle appliqués aux métiers commencent souvent par une question assez simple : peut-on interroger automatiquement un corpus documentaire et obtenir une réponse utile ? Dans le cas de la gestion de l’eau, cette question devient rapidement plus complexe. Les professionnels du secteur travaillent avec des documents nombreux, techniques, hétérogènes et rarement pensés pour être exploités par une interface conversationnelle. Articles scientifiques, rapports institutionnels, guides techniques, décisions de justice, SDAGE, SAGE, PTGE ou corpus privés : l’information existe, mais elle est dispersée, longue à analyser et difficile à croiser rapidement.
C’est à partir de ce besoin très concret qu’a été développé AQUA! (pour l'association du même nom), une plateforme RAG dédiée aux milieux aquatiques, au droit de l’eau et aux politiques territoriales. L’objectif initial était de permettre à l'association de produire plus vite des synthèses documentées. Le projet a rapidement montré que le principal enjeu ne se situait pas simplement dans le choix du modèle génératif. La difficulté n’était pas seulement de faire répondre un LLM, mais de lui donner accès aux bons documents, dans le bon ordre, avec les bonnes règles de lecture.
Le RAG ne suffit pas si le corpus est mal organisé
Le principe du RAG est désormais assez connu : on découpe des documents en fragments, on les vectorise, on les stocke dans une base, puis on récupère les passages les plus proches d’une question avant de demander au modèle de rédiger une réponse. Cette mécanique fonctionne bien pour des démonstrations simples, mais elle devient fragile dès que les corpus portent sur des domaines spécialisés.
Dans les premiers tests, la recherche par similarité montrait vite ses limites. Un fragment pouvait être proche d’une requête sur le plan lexical ou sémantique, sans être réellement pertinent pour y répondre. Un texte associatif, un article scientifique et une jurisprudence peuvent employer les mêmes mots, mais ils ne produisent pas le même type de vérité. Une décision administrative ne se mobilise pas comme un résultat expérimental ; un document territorial n’a pas la même portée selon son périmètre, sa date et son niveau d’opposabilité.
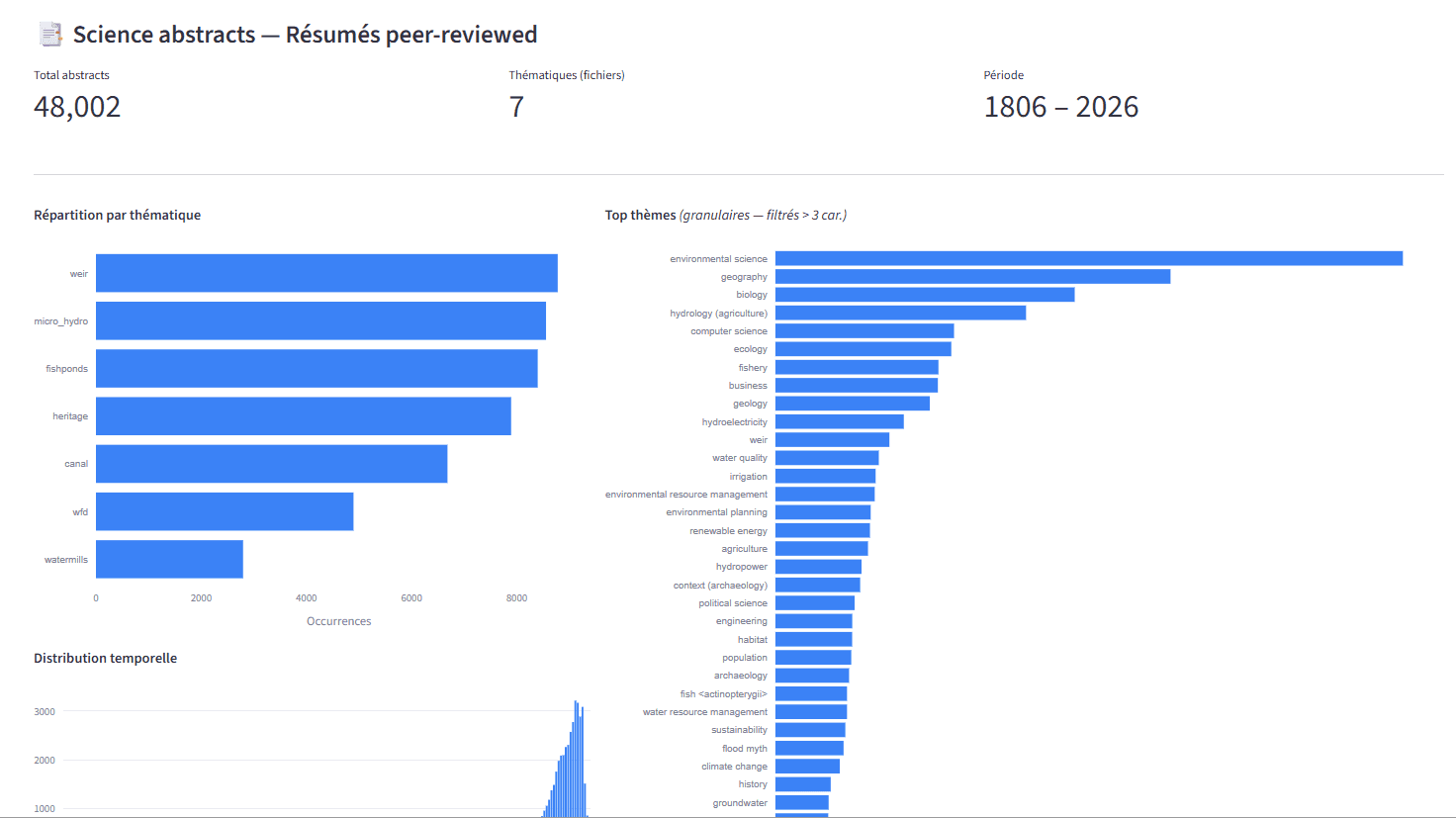
Le choix structurant a donc été de ne pas constituer une grande base unique. La plateforme AQUA! sépare les corpus par nature : science peer-reviewed, abstracts scientifiques, jurisprudence administrative, littérature grise, corpus associatif, corpus réglementaire territorial et corpus client dédié. Chaque base ChromaDB dispose de ses propres paramètres, de son propre pipeline d’ingestion et de ses propres règles d’usage. Au total, l’ensemble représente environ 500 000 chunks : leur valeur vient précisément du fait qu’ils ne sont pas mélangés.
Cette séparation est moins spectaculaire qu’une démonstration d’interface, mais elle conditionne la fiabilité du système. Un agent scientifique doit prioriser les sources peer-reviewed. Un agent juridique doit rester dans le champ de la jurisprudence ou de la recherche juridique contrôlée. Un agent territorial doit savoir naviguer dans les documents de planification. C’est cette architecture des savoirs qui permet au RAG de devenir un outil métier plutôt qu’un simple moteur de recherche augmenté.
L’ingestion documentaire, le vrai cœur du système
Un autre enseignement du projet concerne le temps passé avant même la génération d’une réponse. Dans un RAG professionnel, l’ingestion documentaire représente une part majeure du travail. Il ne suffit pas de déposer des PDF dans un dossier et d’attendre que l’IA fasse le reste : il faut classer, nettoyer, dédoublonner, extraire des métadonnées, contrôler la qualité des fichiers, découper les textes de manière cohérente et maintenir l’ensemble dans le temps.
La plateforme AQUA! repose sur une chaîne d’ingestion incrémentale. Chaque document est d’abord analysé par un LLM de classification rapide, qui extrait son type, ses auteurs, son année, son institution, ses thèmes, ses mots-clés et une citation exploitable. Un hash MD5 permet d’identifier les doublons, y compris lorsque le fichier a été renommé. Le document est ensuite découpé en chunks, vectorisé et ajouté à la base cible, sans réindexer ce qui existe déjà.
Cette logique répond à un besoin : rendre le corpus maintenable. Les bases documentaires évoluent, les clients ajoutent de nouveaux fichiers, la réglementation change, la littérature scientifique continue de progresser. Si chaque mise à jour impose de reconstruire l’ensemble, le système devient coûteux et fragile. À l’inverse, un pipeline incrémental permet d’ajouter de nouveaux documents sans perdre le contrôle sur l’existant.
Le pipeline d’ingestion n’est pas un simple outil de préparation des données ; il devient un actif réutilisable. Chaque nouveau corpus peut être traité avec le même schéma général, tout en conservant ses spécificités métier.
Des agents conçus comme des raisonnements métier
Dans ce projet, il n'y pas un agent généraliste auquel on demanderait de changer de ton ou de longueur de réponse selon la question. Chaque agent correspond à une manière différente de raisonner sur les documents. L’agent Scientifique ne mobilise pas les sources comme l’agent Associatif. L’agent Territorial n’a pas les mêmes contraintes que l’agent Juriste.
Cette spécialisation passe par les chaînes de pensée et par les prompts, mais pas au sens superficiel de ce terme. Les prompts décrivent ici aux agents une méthode d’analyse : hiérarchie temporelle des sources scientifiques, niveaux de preuve, articulation entre données empiriques et travaux fondateurs, distinction entre opposabilité aux tiers et opposabilité aux décisions administratives, identification du bassin versant, du SAGE ou du PTGE applicable. Certains agents intègrent aussi une boucle d'audit logique avant rédaction et un rapport de transparence après génération.
Là se joue une partie importante de la valeur. Un modèle généraliste peut produire une réponse plausible sur l’écologie aquatique ou le droit de l’eau. Mais une réponse plausible n’est pas nécessairement une réponse fiable ni complète. Dans des domaines spécialisés, l’IA doit être contrainte par les catégories du métier, sinon elle risque de simplifier, de mélanger les registres ou de présenter comme établi ce qui devrait être nuancé.
Une architecture sobre pour garder le contrôle
Techniquement, AQUA! s’appuie sur une architecture assez classique : Python, LangChain, ChromaDB, FastAPI, PyMuPDF pour l’extraction PDF, Gemini pour la classification, les embeddings et la génération. Le retrieval combine MMR et MultiQueryRetriever afin d’améliorer la diversité des passages remontés et d’éviter les résultats trop répétitifs. L’interface permet de choisir différents agents, formats de réponse et modes d’analyse, avec authentification, quotas, historique et export des expertises.
Cette sobriété est importante. Dans un projet RAG, la complexité arrive vite : multiplication des corpus, évolution des prompts, nouveaux cas clients, mises à jour documentaires, contraintes de déploiement, suivi des coûts. Une architecture compréhensible, versionnée et documentée devient alors aussi importante que la performance du modèle.
Ce projet a montré que dans les projets d’IA appliqués à des domaines exigeants, le LLM n’est pas le produit à lui seul. Il est une brique dans un système plus large, où la qualité du corpus, la séparation des domaines, les métadonnées, les prompts métier et la maintenance des données comptent autant que la génération finale.
C’est pourquoi il est plus juste de parler ici d’ingénierie de la connaissance que de chatbot documentaire. Le but est de produire une réponse qui respecte les sources, les niveaux de preuve, les règles du domaine et les limites de ce que l’on peut conclure.
Un bon RAG ne cherche donc pas à tout mélanger dans une grande mémoire vectorielle. Il organise les connaissances pour que chaque agent mobilise ce qu’il doit mobiliser, au bon moment et avec le bon niveau de prudence.
C’est probablement l’une des conditions de réussite des IA métier : moins d’effet démonstratif, plus de structure ; moins de réponses génériques, plus de raisonnement encadré ; moins de promesses sur le modèle, plus de travail sur la connaissance qu’on lui confie.
